Chrome中机器人检测原理分析
0x00 背景
使用基于Chrome的机器人技术可以模拟用户操作,从而实现爬虫、薅羊毛等能力。为了避免恶意用户使用这类技术做出危害平台的事情,需要能够检测当前的浏览器环境是否安全。
0x01 Chrome远程调试
在Chrome中开启远程调试是最常见的机器人技术,很多框架,比如:Puppeteer、Selenium等都是使用了这种技术。该技术主要是在命令行参数中增加了--remote-debugging-port=${port},表示会开启指定的调试端口,可以通过WebSocket协议来调试页面,包括执行JavaScript、获取DOM节点、获取/拦截网络请求等,本质上是开启了一个远程的DevTools。
1 | async def screenshot_page(url: str, output_path: str = "screenshot.png"): |
为了验证这些库能否被检测,我写了一个脚本,会以正常模式打开https://bot.sannysoft.com/这个网站,截图如下:
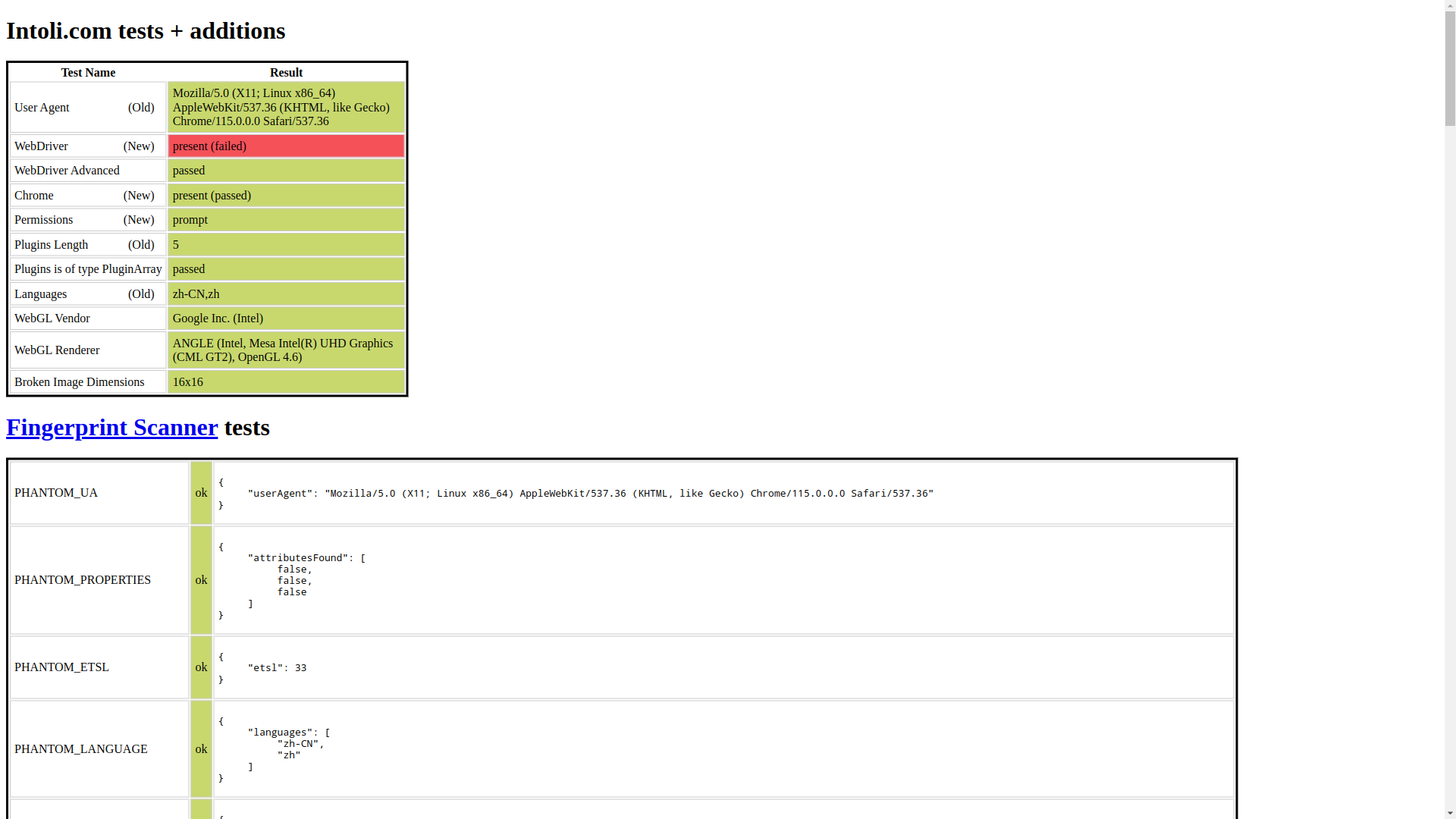
可以看到,webdriver检测这项失败了。我们来看下此时的Chrome完整启动命令行:chrome --disable-background-networking --disable-background-timer-throttling --disable-breakpad --disable-browser-side-navigation --disable-client-side-phishing-detection --disable-default-apps --disable-dev-shm-usage --disable-extensions --disable-features=site-per-process --disable-hang-monitor --disable-popup-blocking --disable-prompt-on-repost --disable-sync --disable-translate --metrics-recording-only --no-first-run --safebrowsing-disable-auto-update --enable-automation --password-store=basic --use-mock-keychain --no-sandbox --remote-debugging-port=42205 --user-data-dir=/home/drunkdream/.local/share/pyppeteer/.dev_profile/tmppmvr4w1i about:blank。
命令行很长,但可以看到一个很显眼的参数 --enable-automation,加了这个参数以后,会导致 navigator.webdriver 返回 true,这也是截图中失败项的检测原理。
查看 pyppeteer 源码可以发现,--enable-automation 参数是默认启动参数,为了去掉这个参数,将上面的python脚本修改如下:
1 | async def screenshot_page(url: str, output_path: str = "screenshot.png"): |
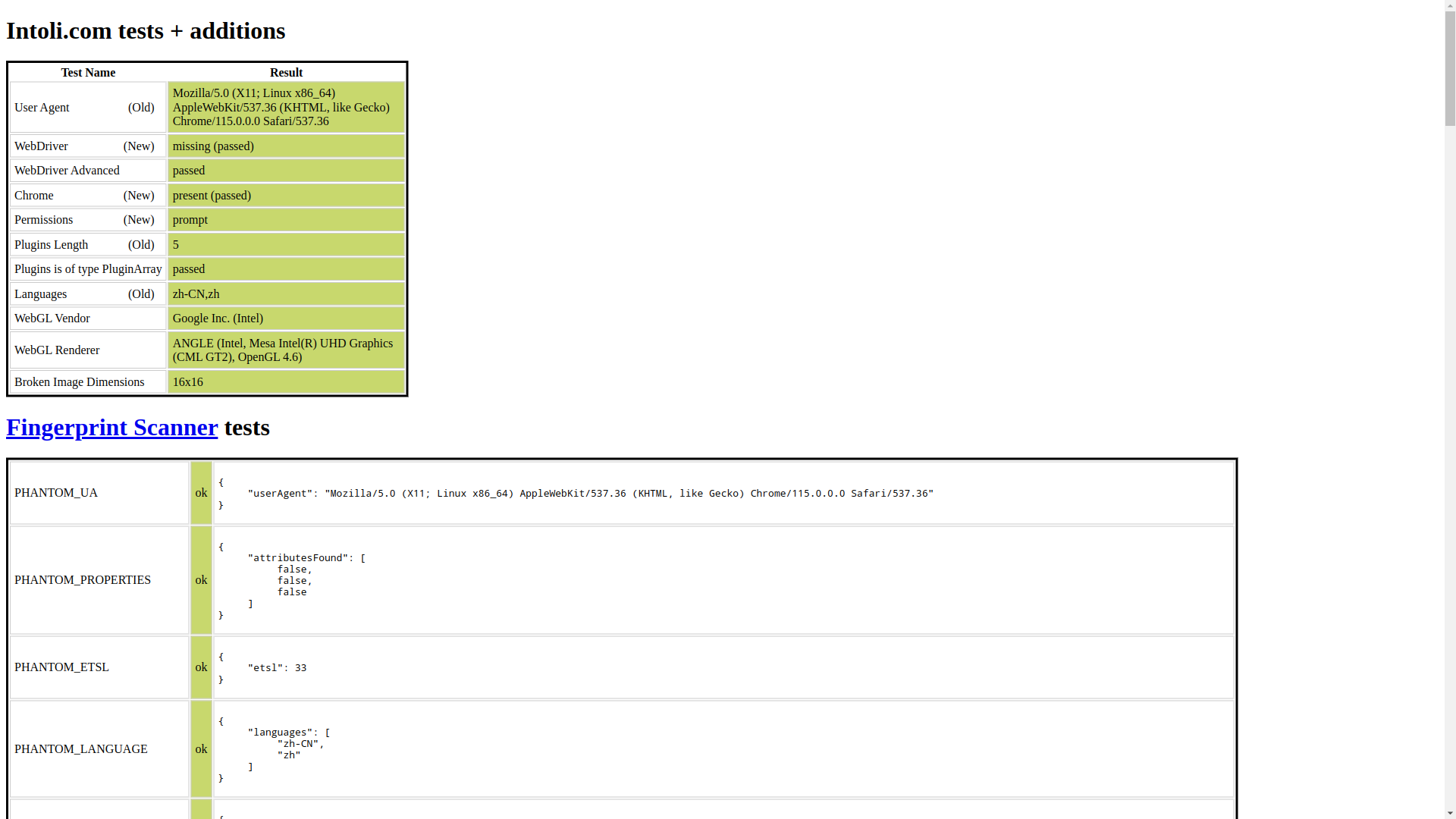
可以看到,所有检测项都通过了。
0x02 Headless 模式
如果要在服务器/容器等环境中使用 Chrome,Headless 模式是最常见的一种方式。Chrome 官方文档中有对 Chrome Headless 模式的介绍。
我们将上面 python 脚本中的启动参数列表中增加 --headless,运行后截图如下:

发现红了一片,但如果启动参数改为 --headless=new,运行后截图如下:
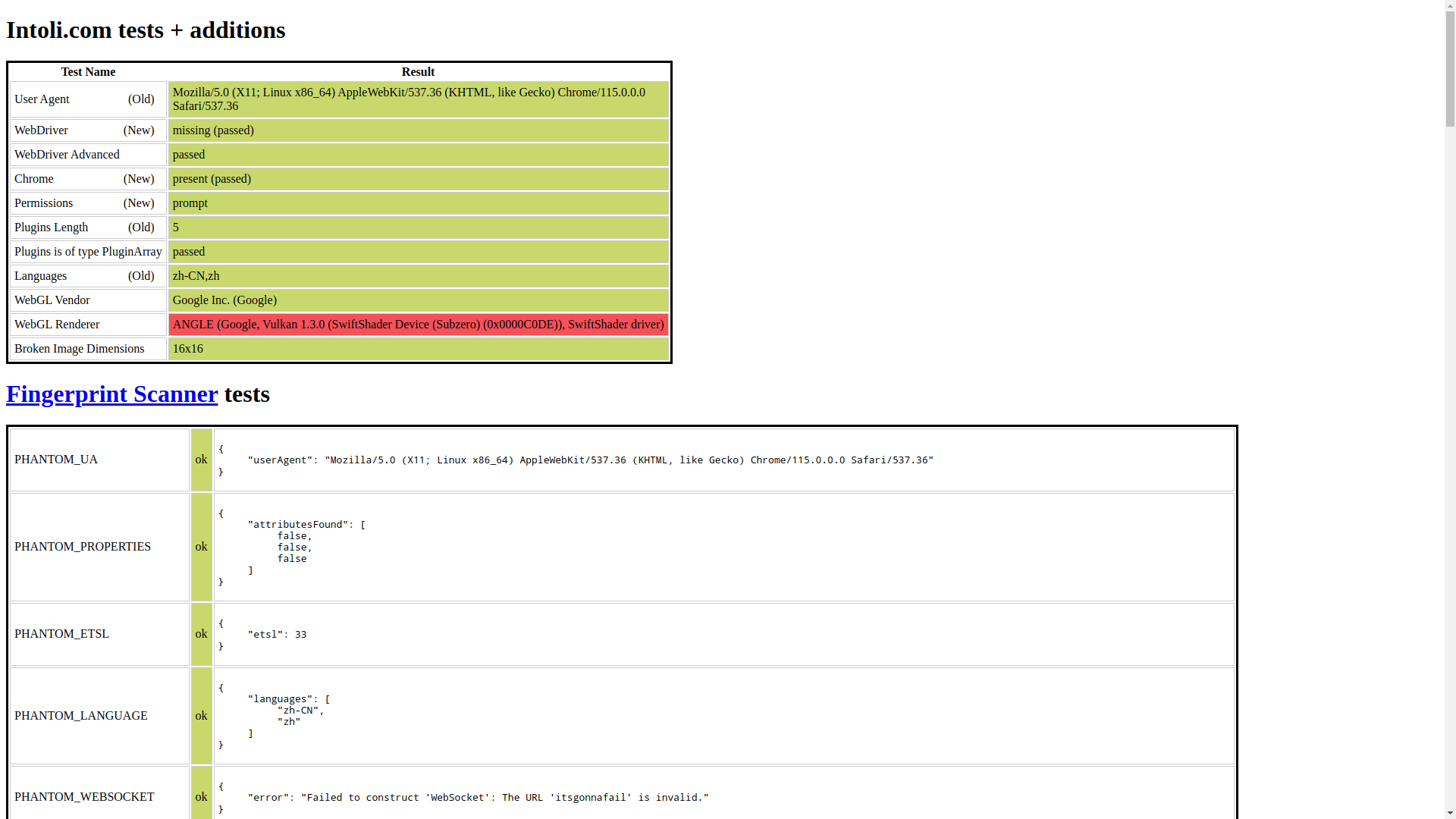
此时只剩下 WebGL Renderer 这一项是红色的了。那 --headless 和 --headless=new 到底有什么区别呢?
Chromium 源码中 headless 是作为一个独立的目录存在,因此,在 Chrome 中有头模式与无头模式是两套不同的实现,这也是为什么它们存在如此多不一致的原因。
从 Chrome 112 版本开始,Chrome 提供了新的 Headless 实现,与普通模式使用了同一套代码,使得无法再使用两者的差异来进行 Headless 的检测。不过,直到 Chrome 128 版本(对应 Commit),新版本的 Headless 实现才成为默认实现;而 Chrome 112 - 127 版本则需要使用 --headless=new 参数才能生效。
而上面 WebGL Renderer 的结果,可以使用以下代码来检测:
1 | function getGPUInfo() { |
不过发现开启 Headless 的情况下,这里会始终显示 SwiftShader,而不是使用硬件显卡。但如果仅凭这一点就断定用户使用了 Headless 不是很靠谱,因为当命令行中存在 --disable-gpu 参数时,也会这样显示。
0x03 总结
对于 < 112 版本的 Chrome,尽量不要开启 Headless,否则会存在大量特征可以被检测出来;对于 112 - 127 版本的 Chrome,需要使用 --headless=new 参数开启 Headless;>= 128 版本的 Chrome,则可以放心打开 Headless 模式。
使用第三方库打开 Chrome 时,一定需要确保命令行参数中不存在 --enable-automation。